

### 前言
在数字时代,数据分析和预测已经成为各行各业不可或缺的工具。无论是金融投资、市场营销,还是日常生活中的决策,准确的数据预测都能为我们提供有力的支持。"澳门一码一码100准确"这一概念,虽然听起来有些神秘,但实际上它代表了一种通过精确的数据分析和模型预测来实现高准确率的方法。本文将详细介绍如何通过一系列步骤来实现这一目标,无论你是初学者还是进阶用户,都能从中获得实用的知识和技能。
### 第一步:数据收集
#### 1.1 确定数据来源
首先,你需要明确数据的来源。对于"澳门一码一码100准确"这一任务,数据可能来自于历史开奖记录、市场趋势分析、用户行为数据等。确保数据来源的可靠性和合法性是至关重要的。
**示例:**
- **历史开奖记录:** 从澳门彩票官方网站或可信的第三方数据平台获取历史开奖数据。
- **市场趋势分析:** 通过金融数据平台获取相关的市场数据。
#### 1.2 数据类型和格式
了解数据的类型和格式有助于后续的数据处理。常见的数据类型包括数值型、文本型、时间序列等。数据格式可以是CSV、Excel、JSON等。
**示例:**
- **数值型数据:** 开奖号码、赔率等。
- **时间序列数据:** 历史开奖时间、市场交易时间等。
#### 1.3 数据收集工具
选择合适的数据收集工具可以提高效率。常用的工具包括Python的`pandas`库、R语言的数据处理包,以及各种API接口。
**示例:**
- **Python的`pandas`库:** 使用`pandas`库可以方便地从CSV文件或数据库中读取数据。
- **API接口:** 通过调用官方API接口获取实时数据。
```python
import pandas as pd
# 从CSV文件读取数据
data = pd.read_csv('historical_data.csv')
# 打印数据的前几行
print(data.head())
```
### 第二步:数据清洗
#### 2.1 处理缺失值
数据清洗的第一步是处理缺失值。缺失值可能会影响模型的准确性,因此需要采取适当的方法进行处理。
**示例:**
- **删除缺失值:** 如果缺失值较少,可以直接删除。
- **填充缺失值:** 使用均值、中位数或前一个值填充缺失值。
```python
# 删除含有缺失值的行
data_cleaned = data.dropna()
# 使用均值填充缺失值
data_filled = data.fillna(data.mean())
```
#### 2.2 处理异常值
异常值是指明显偏离正常范围的数据点。处理异常值可以提高模型的稳定性。
**示例:**
- **删除异常值:** 通过设定阈值删除异常值。
- **替换异常值:** 使用均值或中位数替换异常值。
```python
# 设定阈值,删除异常值
threshold = 3
data_cleaned = data[(data - data.mean()).abs() < threshold * data.std()]
```
#### 2.3 数据标准化
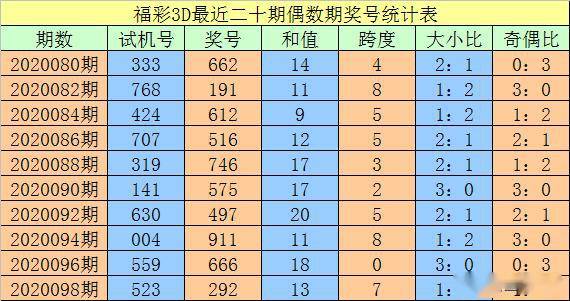
数据标准化是将不同尺度的数据转换为统一尺度的过程。标准化可以提高模型的收敛速度和准确性。
**示例:**
- **Z-score标准化:** 将数据转换为均值为0,标准差为1的分布。
- **Min-Max标准化:** 将数据缩放到[0, 1]区间。
```python
from sklearn.preprocessing import StandardScaler
# 创建标准化器
scaler = StandardScaler()
# 标准化数据
data_scaled = scaler.fit_transform(data)
```
### 第三步:数据分析
#### 3.1 描述性统计分析
描述性统计分析可以帮助你了解数据的总体特征,包括均值、中位数、标准差等。
**示例:**
- **均值:** 数据的平均值。
- **中位数:** 数据的中位数。
- **标准差:** 数据的离散程度。
```python
# 计算均值、中位数和标准差
mean_value = data.mean()
median_value = data.median()
std_value = data.std()
print(f"均值: {mean_value}, 中位数: {median_value}, 标准差: {std_value}")
```
#### 3.2 探索性数据分析(EDA)
探索性数据分析是通过可视化和统计方法来探索数据的模式和关系。
**示例:**
- **直方图:** 展示数据的分布情况。
- **散点图:** 展示两个变量之间的关系。
```python
import matplotlib.pyplot as plt
import seaborn as sns
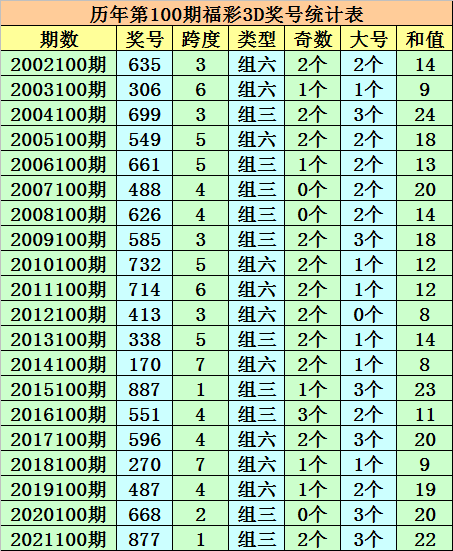
# 绘制直方图
sns.histplot(data['开奖号码'], kde=True)
plt.show()
# 绘制散点图
sns.scatterplot(x='时间', y='开奖号码', data=data)
plt.show()
```
#### 3.3 相关性分析
相关性分析可以帮助你了解不同变量之间的相关性。相关性系数通常在[-1, 1]之间,正值表示正相关,负值表示负相关。
**示例:**
- **皮尔逊相关系数:** 衡量线性相关性。
- **斯皮尔曼相关系数:** 衡量非线性相关性。
```python
# 计算皮尔逊相关系数
correlation_matrix = data.corr()
# 打印相关系数矩阵
print(correlation_matrix)
```
### 第四步:模型选择与训练
#### 4.1 选择合适的模型
根据数据的特征和任务的目标,选择合适的模型。常见的模型包括线性回归、决策树、随机森林、支持向量机等。
**示例:**
- **线性回归:** 适用于线性关系的数据。
- **随机森林:** 适用于非线性关系的数据。
#### 4.2 数据集划分
将数据集划分为训练集和测试集,以便评估模型的性能。通常,训练集用于训练模型,测试集用于评估模型。
**示例:**
- **训练集:** 用于训练模型的数据。
- **测试集:** 用于评估模型的数据。
```python
from sklearn.model_selection import train_test_split
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(data.drop('目标变量', axis=1), data['目标变量'], test_size=0.2, random_state=42)
```
#### 4.3 模型训练
使用训练集对模型进行训练。训练过程中,模型会学习数据的模式和规律。
**示例:**
- **线性回归模型:** 使用训练集训练线性回归模型。
- **随机森林模型:** 使用训练集训练随机森林模型。
```python
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
# 训练线性回归模型
linear_model = LinearRegression()
linear_model.fit(X_train, y_train)
# 训练随机森林模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
```
### 第五步:模型评估
#### 5.1 评估指标
选择合适的评估指标来评估模型的性能。常见的评估指标包括均方误差(MSE)、均方根误差(RMSE)、R²等。
**示例:**
- **均方误差(MSE):** 衡量预测值与实际值之间的差异。
- **R²:** 衡量模型解释数据的能力。
```python
from sklearn.metrics import mean_squared_error, r2_score
# 预测测试集
y_pred_linear = linear_model.predict(X_test)
y_pred_rf = rf_model.predict(X_test)
# 计算MSE和R²
mse_linear = mean_squared_error(y_test, y_pred_linear)
r2_linear = r2_score(y_test, y_pred_






 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...